Deep Learning Algorithms are Function Estimators
Before I begin this is a very “hand wavy” blog post. This is simply an idea i’ve been thinking about. In no way is this a technical post or should be treated as such.
When reverse engineering a piece of code, the ultimate goal is understand its operation, and then to either replicate it or to exploit it. Deep learning takes a similar approach to a reverse engineer, except in a slightly different manner. Supervised deep learning algorithms are given both the inputs and outputs and the goal is to estimate the relationship.
We can represent a function as input, a system, and an output.
![input->[system]->output](/assets/system.png)
A model can then take those inputs and outputs and estimate the system.
Say you had a function like the one below and you wanted to estimated its functionality.
int fizzbuzz(int n) {
if (n % 15 == 0) {
printf("FizzBuzz\n");
} else if (n % 3 == 0) {
printf("Fizz\n");
} else if (n % 5 == 0) {
printf("Buzz\n");
}
return 0;
}A model to estimate this function could look something like the figure below.
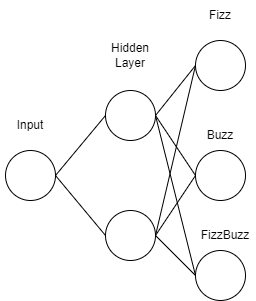
To train an estimator for this function you could fuzz it with a few hundred inputs (fuzzing should grow with complexity of the function) and log the outputs. Then you could train a model on the collected inputs and outputs. Soon enough you would have an estimator for the function. As you can see, we can represent a function in with a neural network. The output of our model will be a probably distribution, giving probabilities for each of the possible outputs. So you maybe thinking well how does idea apply to far more complex deep learning tasks like selfdriving.
In the case of selfdriving, the function we want to estimate is driving. The goal is to create a function estimator that can drive a car as well or better than a human. For humans we can estimate driving by taking in our surrondings and then driving according to them. Human’s drive with their eyes and this can be seen when humans play driving games like Mario Kart or Forza. The outputs are a bit more discrete. The outputs of driving function are the path the car should travel and the controls. The controls being steering angle, gas, brakes, etc.
Companies like Telsa and Comma AI are both creating self driving systems. They are both taking different approaches but ulitmately have the same goal. Telsa utilizes several cameras around the vehicle and various sensors. Comma uses only a few cameras mounted to a device that is mounted below the rear view mirror of the car. Comma also utilizes on board sensors on the vehicle. Both systems collect many miles of driving data, including video, steering angles, acceleration, etc. Tesla’s system is very much like a game. They try to model the environment and then ask a driving agent what should the driver do. Comma uses a very end-to-end approach of asking a model given these video frames, what should the driver do. Both models are somewhat recursive due to the time series nature of the problem.
So given that we can model driving as a function, what is to say that we can’t model other things as functions? With this idea in mind we can look at the world as a very large function. The inputs for such a function are near infinite, yet humans have nearly perfected the estimation of the world, as we have lived on Earth for a very long time. We can think of evolution as back propagation and living as a forward iteration.
Thinking about the world in this manner allows us to explore more ideas of simulation. If we could estimate complex functions, can we estimate the universe? Are we living in an estimation of the universe? We probably won’t ever know as it is probably unfalsifiable. Assuming we do live in an estimation of the universe, the estimation may not be perfect, but probably unobservable.